




国会では統計不正問題をめぐって見当はずれの質疑が行われているが、「アベノミクス偽装」という類の陰謀論はすべて誤りだ。2018年1月からの毎月勤労統計のシステム更新は、統計的精度も安定性も上がる改善だった。このとき結果として賃金が「上振れ」したが、問題はそれより2017年まで賃金が「下振れ」していたことだ。
立憲民主党にアドバイスしている明石順平という弁護士は、上振れが「ベンチマーク更新」の影響だというが、システムを更新したら影響が出るのは当たり前だ。2018年の場合は経済センサスに合わせて大企業を増やし、サンプルを毎年1/3入れ替える「ローテーション・サンプリング」にしたが、それで数字が変わっても法的な問題は発生しない。
問題は賃金の変化のうち、統計法違反が原因になっている部分だ。2003年に調査計画を変更したとき総務省統計委員会の承認を受けなかったのは違法だから、予算案を修正して過去の給付に遡及して支払う異例の対応が取られた。ベンチマークやサンプルの変更が原因なら、予算の修正は必要ない。
厚労省は、2017年まで賃金が下振れしていたことにいつ気づいたのだろうか。去年6月当時の政策統括官Jは「抽出調査により実施していたことを認識していなかった」と供述しているが、これは2003年から何度も事務連絡を出しているのでおかしい。この疑問への答は、次の二つのうちどちらかだ。
- 厚労省の官僚は事務連絡も読まない無能である
- 彼らは嘘をついて何かを隠している
1の確率もゼロではないが、2の確率が高い。この場合ありそうなのは、抽出調査は法的には問題があるが、復元したので誤差はないと考えたということだろう。当初は問題ないと考えていた(悪意はなかった)ことは、厚労省が親切に次の図のような「変更が無かった企業に絞った参考値」を出したことでもわかる。
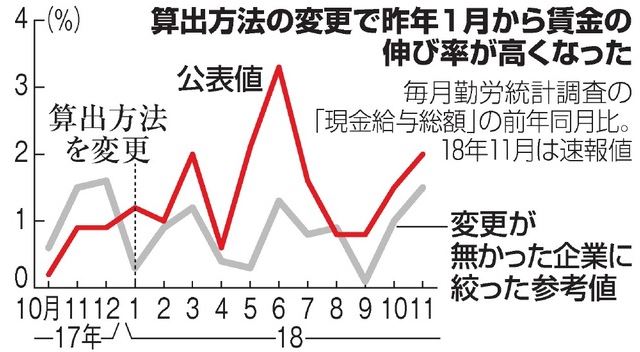
朝日新聞デジタルより
ところが統計委員会で日銀や民間の委員が、この公表値と参考値の大きな乖離を見て、ますます疑念を強めた。彼らが一次データの公開を求め、厚労省が古いソースコードをチェックして初めて(おそらく去年10月から12月の間)、復元処理をやっていないことがわかったのだろう。その誤差は統計的には大したことないが、違法なので失業給付などに影響することがわかり、逃げられなくなった。
だから普通なら、今回のミスは隠し通せた可能性が高い。官庁のデータがタコツボ化し、一次データを見せない状況では、こういう事件は防げない(他の役所にもあるおそれが強い)。これを機に官庁の統計データを共有して総務省に一元化し、統計処理システムをオープンソースにしてはどうだろうか。
調査員が出向いてやっている非効率的な調査もクラウド化し、調査員ではなく記入する企業に金を払うべきだ。「国家統計局」を創設しろという話もあるが、組織いじりより情報システムの改善が重要だ。野党もくだらない陰謀論より、こういう実務的な問題を追及すべきだ。









