



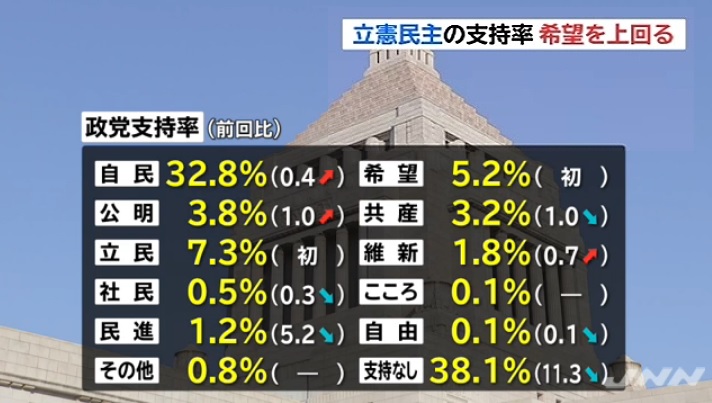
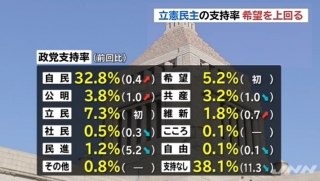
画像はJNN世論調査
先日、打ち合わせをしている際に、選挙予想の話になった。プロの選挙プランナーは基礎データを所有していて、そのデータに、取材に基づいた独自の情報を掛け合わせていく。選挙予想をするには、各プランナーの恣意的な意思が強く反映されることから、予想にはかなりのバラつきが生じる。これがバイアスというものである。
今回は予想が難しい選挙といえる
18日、JNNが行った世論調査で、立憲民主党の支持率が希望の党の支持率を上回ったことがわかった。各政党支持率では、自民党の32.8%が最も高いが、次に高かったのは立憲民主党の7.3%、希望の党は5.2%に留まった。調査方法は、RDDで全国18歳以上の男女、有効サンプル数が1171件、標本誤差を±2.8%としている。
つい数日前までは、「希望の党大躍進!」「小池氏出馬で希望の党政権交代!」と予想したプランナーも多かった。立憲民主党が誕生した際に、ここまで支持率を伸ばすことを予想したプランナーは皆無だった。まるでギャンブラーのごとく適当な数字を公表する専門家もいたが、それだけ注目度が高く、予想が難しい選挙ともいえるのだろう。
また、RDDは世論調査で最も多く使用される手法である。一般固定電話に機械がランダムに電話して結果を集計する。性別、年代別、地域別、職業別の構成比が補正されていないこと、独身者の固定電話契約率が3割未満という実情。さらに、携帯電話番号が除外され、日中の荷電であることを考えると、この調査にも限界がある。
今回の、JNNの世論調査は調査結果は標本誤差を公表しているが、一般的には公表しないことのほうが多い。公表しているということは、結果のバラつきを想定し補正の必要性を示唆していることになる。この点は評価できると思われる。今後は可能ならば、信頼係数についても明らかにしてもらいたい。有意性が明らかになれば分析はより楽になる。
補正をかけていないので、ノイズの除去が困難ではあるが、データとしては見るべきものがある。本来は各選挙区の状況を丹念に精査したうえで予想するが、あくまでもデータとして何が見えるかという点について整理したい。
公表データから見えてくるもの
標本誤差はサンプル数が1000件の場合、理論的に±3.1%の範囲に収まる。調査は1171件であることから、±3.0%と仮定する。JNNの発表している±2.8%の根拠が不明瞭であることから、±3.0%を使用する。データ上の仮説は次のとおりとなる。
立憲民主党の政党支持率を7.3%とした場合、±3.0%であることから、支持率は10.3%~4.3%の範囲に収まる。希望の党の政党支持率は5.2%であるから、支持率は8.2%~2.2%の範囲に収まる。さらに、立憲民主党の支持率最大10.3%と希望の党の支持率最小2.2%とした場合、8.1%との差が生じる可能性があることをデータ上では示している。
また、現在の情勢を鑑みれば、立憲民主党の支持率は上昇傾向である。一方、希望の党の支持率は下降傾向にある。投票日まで残り3日として、この情勢が大きく変化することは考えにくいことから、立憲民主党の支持率が、希望の党を上回る可能性が高いといえる。むしろ、支持率の差は拡大していく可能性が高いのだろう。
政党支持率がそのまま投票行動に反映されるとはいえないが、仮に、投票行動に反映された場合のシミュレーションをおこなってみる。前回総選挙投票率52.66%を想定し、有権者の支持率7.3%の場合、選挙区+比例=800万票程度を獲得する可能性がある。有権者の支持率10.3%の場合には、1200万票程度を獲得する可能性がある。
シミュレーションをした場合、支持率7.3%の場合は40±10議席、支持率10.3%の場合は60±10議席を予想できる。これは、概ね、報道されている結果を照射していることになる。40±10議席程度の獲得であれば、現在の報道結果を反映し、60±10議席の獲得となると、野党第一党の議席となる。
しかし、立候補者数78名を考えると、そこまでは届かないことが考えられる。さらに、立憲民主党は全ブロックに比例単独候補が立候補していない。投票数次第では、議席が割り当てられるであろうブロックもあり、議席がムダになる可能性もある。
自分で分析をしたいと思ったら
今後、選挙までの残り3日で、各社が分析結果を公表すると思われる。標本誤差は、1000サンプルなら2~3%、500サンプルなら2.7%~4.5%、100サンプルなら6%~10%になる。各社の支持率の結果に、誤差を当てはめれば投票数が予想できる。予想できたら、過去の選挙結果(データは前回選挙のもの:総務省)の数字を当てはめれば予想が可能になる。
私は分析をする際に、SPSSとClementineを使用している。型落ちだが、基本的な因子分析やデーターマイニングに困ることはない。元々は20万円近くするソフトで一般的に購入すると高額だが、学生であればアカデミック版、中古版なら廉価に入手可能である。用途が広いことから選挙予想以外にも使用できるので一度試してみることをお勧めしたい。
なお、私は選挙プランナーではない。本記事で紹介した手法は、あくまでも一つのケースに過ぎないが、分析業務に覚えがある人なら独自結果を導き出すことができるはずだ。
一方で予想にも限界がある。データは想定外のことに弱い。顧客分析を例にとれば、想定外の顧客の属性は導き出すことはできない。例えば、「髪型が七三、ヒョウ柄スーツを着用した男性は何を買うのか」と購買特性を知りたくてもデータがないのと同じである。今回の、立憲民主党の一件は想定外だったと考えることができる。
参考書籍
『朝日新聞がなくなる日 – “反権力ごっこ”とフェイクニュース』(ワニブックス)
尾藤克之
コラムニスト
<第3回>アゴラ出版道場開催のお知らせ
ネットから著者デビュー!第3回「アゴラ出版道場」11月4日開講。お待たせいたしました。商業出版を目指す著者志望者を対象にした第3回「アゴラ出版道場」を、11月4日から開講します(12月16日まで隔週土曜、全4回)。申込み〆切は10月27日の正午です。

お問い合わせ先 [email protected]








