



こんにちは。新宿区議会議員の伊藤陽平です。
文系の初心者からAI議員を目指す宣言を行い、ここ1年くらいで改めてプログラムや数学を学びなおしながら、政策立案におけるコンピュータの活用について研究を続けてまいりました。
本日は、今回の議会で質問するテーマの一つでもある、「テキストマイニング」についてお伝えします。
一般的に統計で用いられるデータとは、四則演算など計算を行うことができるものです。
ICT化の時代ではデータの管理や活用が求められていますが、まず想定されるのは、表やグラフを作成して分析することです。
一方で、新宿区では区民意識調査を行っていますが、選択式の設問ように数値化できるものだけではなく、自由記述による設問もあります。
また、コールセンターでは音声を通じて日々様々なご意見が届いています。
例えば、区民意識調査では、数値で表現可能な部分はExcelで扱える形式で公開されています。
しかし、自由記述については、抜粋されたものが報告書に記載されている程度ですが、担当者の主観が反映されてしまう可能性もあるでしょう。
テキストデータを人力で評価すると、主観が反映されることに加え、多大なリソースがかかってしまいます。
やはりコンピュータで分析をすることを検討しなければなりません。
そこで、テキストマイニングという手法を導入することを検討しました。
この手法では、文章を単語等に分割し、出現頻度やキーワードの関連性等を分析します。
テキストマイニングに取り組む様子は、先週のAbamaTVでも一部取り上げられました。
ちょうどTwitterで英語のテキストを分析しているシーンが放送されましたが、これは外国人観光客が増加することを見込んで、新たな課題を発見しようと考えたからです。
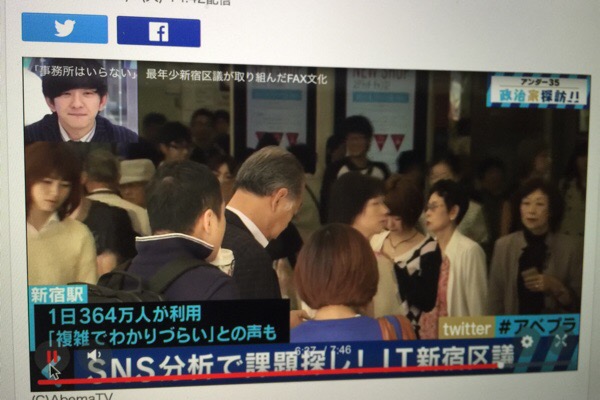
「Shinjuku」という言葉を含む投稿が行われる時、その投稿の内容は「Station」と関連が強い、という話をしていたシーンが報じられていましたが、
「そんなの分析しなくても見ればわかるw」
という厳しいコメントもありました。
その後、新宿駅の映像も流れ、
「1日364万人が利用 『複雑でわかりづらい』との声も」
というテロップが出てきたので、編集の都合上わかりやすいテーマを選ばれたのではないかと思います。
ご存知の通り、新宿駅は乗降者数世界一のターミナル駅です。
「新宿ダンジョン」というダンジョンRPG的なゲームが登場するほど複雑な駅であり、課題が山積みであることは誰が見ても明らかなことです。
番組ではたまたまStationという単語について話していたシーンが出ていますが、もちろん他のキーワードについても議論を重ねていました。
テキストデータをエビデンスにすることは必ずしも適切ではないことを踏まえた上で、個人的な意思や主観を最大限排除しながら仮説を立てるためには、大変有効なものだと言えます。
さて、テキストマイニングに関しては、PythonやR言語で解析を行うことが一般的で、プログラムの知識が必要です。
しかし、最近ではコードの記述が不要な無料ソフトで研究が行われる事例も珍しくありません。
このような取り組みも行われています↓
形態素解析を用いたアンケート調査自由記述欄 の分析手法に関する研究 ~路面電車利用意識調査データを用いたケース スタディ~
東京都交通局建設工務部の方や、大学の研究者の方が関わっていますが、分析に用いられたソフトはフリーのものです。
テキストマイニングは公的機関においても導入を検討していくべきでしょう。
—
改めて議会の期間に入ったらご報告しますが、新宿区のデータ活用に関する取り組みは、急速に進化を遂げています。
今回の議会質問を作成する際に、専門家の方にボランティアとしてご協力をいただきながら調査を進めてきました。
データ活用の分野においては、民間の知恵を活用しながら研究を続けてまいります。
それでは本日はこの辺で。









