



池田信夫氏の「基本再生産数を捨てて『K値』を使ってみた」というタイトルを見てちょっと書きます。

jamessharpe2/flickr:編集部
「K値」とは、基準日からd日後のK(d)が、累計感染者数N(d)と7日前のN(d-7)から
K(d)=1-N(d-7)/N(d)
と定義される、測定値から簡単に導出される量です。この「K値」を使う理由は次のような点だと思います。
- 積分量の関数なので生データより安定した推移が観察できる
- 非常事態宣言、自粛等の効果が容易に見える
- ピークアウト等の振舞が生データより早めに認識できる
1. は確かに「K値」の利点です。問題はこれで何を見るかです。
2. は、非常事態宣言等の人為的な措置を行わなかったデータがなければ無理です。なにせ「K値」は結果の観測量にすぎませんので、違った条件での結果は予測できません。例えば、自粛した場合としない場合で、他の前提も異なっていて、最終的に観測結果が同じであれば、自粛の効果を「K値」では判定できません。これは前回論じたとおりです。
3. は、感染収束の様子等は安定したデータなので細かい解析、予測ができる可能性がありますが、ピークアウトの兆候が生データより幾分早く分かるという判断をするのは大変危険です。この「K値」は、感染拡大傾向の時上昇します。しかし拡大速度が指数関数的になると、その定義から一定値に近づきます。これは所謂ピークアウトの振舞と似ていますから非常に危険です。真逆の指標になってしまいます。
図1は、日本全体の新規感染者数の日毎変化です。感染から2週間で患者と判定された人数です。シミュレーションでは観測値をフィットするように初期感染者分布を定めています。詳細は前回の記事「自粛は必要だったか。モンテカルロシミュレーションで検証した」を参照してください。
図1
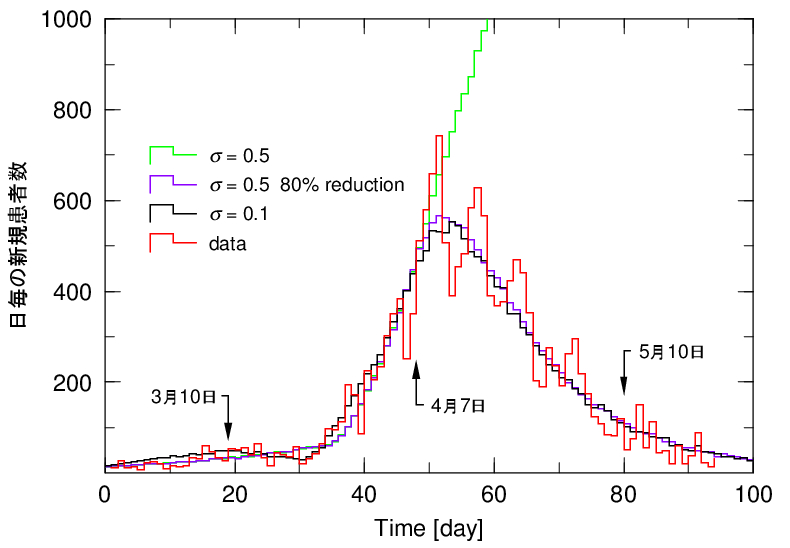
σはモデルの中で接触率を示すパラメータです。日本は比較的小さいσの値で合わせることができます。結果は黒線です。良く合っています。
次に、このσを0.1から5倍の0.5にします。感染拡大期をフィットするように初期条件を変えています。感染力が強力になりますから、感染拡大は指数関数的に増大し(緑線)、収束しません。
この条件のもと、4月7日からσを80%減少0.1にします。結果は紫線です。ピーク以後はほとんど最初のσ=0.1の結果に重なっています。これが前回も行ったシミュレーションによる自粛の検証です。
さて、ここからです。この3つの結果と観測データから「K値」を計算して比較しました。図2です。
図2
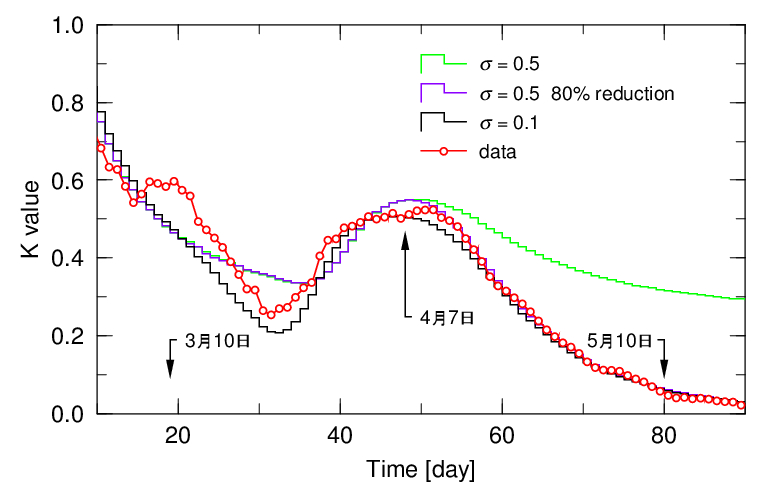
3月10日の近傍は、データもシミュレーション結果も、統計が悪く、我々も注意深くフィットしていないので無視することにします。まずは、自粛を行った結果(紫)と行わなかった結果(黒)は当然区別できません。
次に、4月7日周りのピークの形については、確かに患者数のデータより前側に少し移動しているように見えます。しかしこれは、実際の患者数の変化がピークに向かって上昇率が大きくなって、これを反映して「K値」が緩やかになったもので、ピークアウトの兆候の真逆です。何よりの証拠に、感染拡大が指数関数的になっている緑線の「K値」は、同じ傾向を示します。
今、日本のデータだけでなく、中国、米国のデータを用いたレポートを準備中です。








