



仁井田 浩二 RIST(一般財団高度情報科学技術研究機構)、理学博士
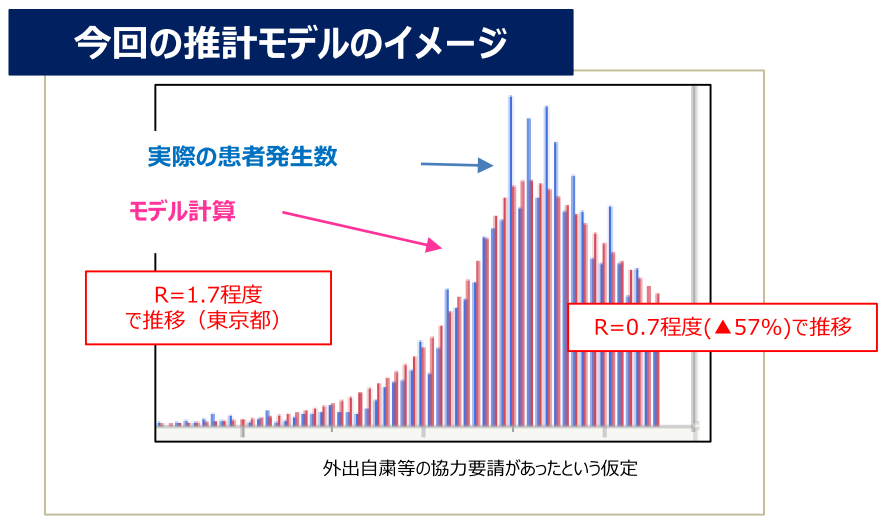
6月19日の新型コロナ専門家会議で、初めて西浦モデルの下図のようなベンチマーク(観測値との比較)らしきものが出てきました。
図1
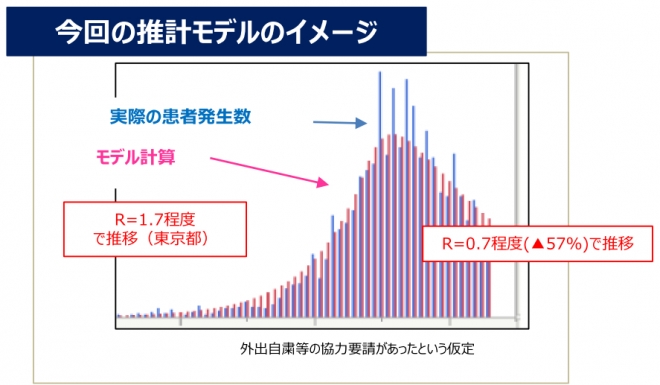
表記されているコメント全てに違和感があります。「推計モデルのイメージ」、イメージというのは何でしょうか。「R=1.7程度で推移(東京都)」、「R=0.7程度で推移」、程度と言われるとモデル計算の入力なのか、観測値からの推察なのかもよく分かりません。一番ひどいのは、右側のコメントの囲い枠 R=0.7程度(▲57%)で推移 が、あたかも図を隠すように設置されており、更に、データは最近まで続くはずなのにそこで切られていることです。
そこで、モンテカルロシミュレーションを用いて検証してみました。これまでの計算では、私独自の実効再生産数Rを定義していましたが、紛らわしいので、通常のRの定義に変更しました。(*注)
図2
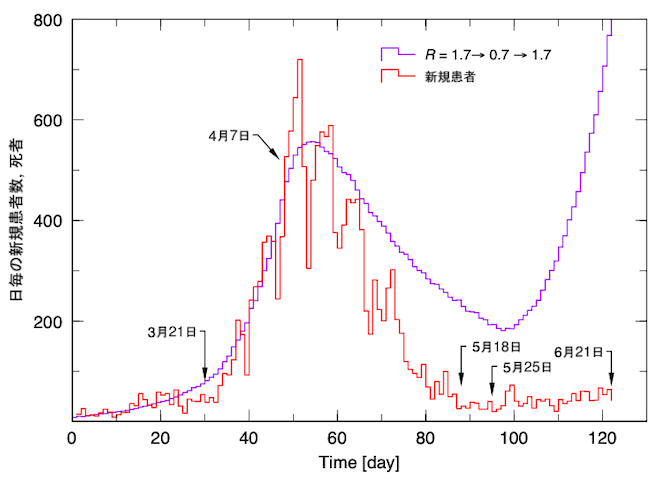
図2は、前回と同様の方法で西浦モデルにあるR=1.
第1波の細かい構造はフィットできませんが、この条件でピークアウトまではフィットできました。このフィットの結果では、感染入国者数が2000人でしたから、逆に感染入国者数2000人でピークを再現しようとすると、どうしてもR=1.7が必要になることも分かりました。
問題は、ピークの後、収束期の傾きです。西浦氏はR=0.7を設定していますが、図2が示すように、この値では全くデータを再現しません。図1の問題点は、既にデータと計算値がずれているであろう所をコメント囲い枠で隠し、更に、それ以後のデータと計算値の比較をカットしていることです。
5月25日に緊急事態宣言の解除でR=0.7から自粛前のR=1.7に戻すと、図2のように急激に患者数が上昇します。自粛解除時の変化が重要な情報を与えるということを、この連載で何回も述べました。その情報を利用するどころか、ベンチマークから外しているのは信じられません。この期間についてどのような扱いをしているのでしょうか。
図3
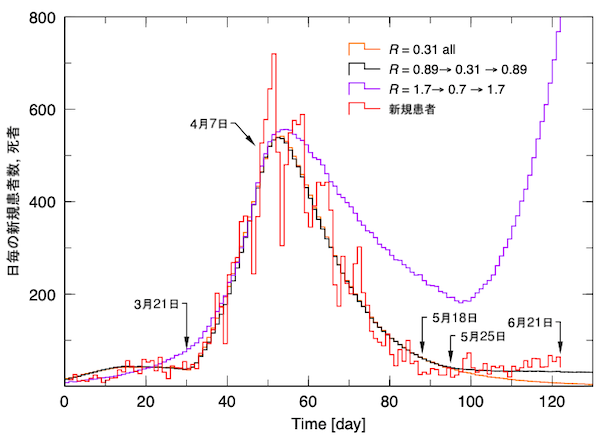
図4
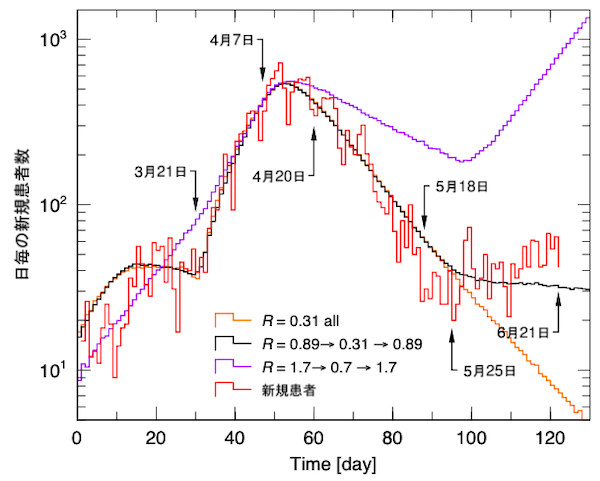
図3と図4(図3の対数表示)は、同じ図に前回の結果、R=0.89でスタートし、自粛でR=0.31に減少させ、5月18日に自粛解除してR=0.89に戻した結果です。同じ図に、R=0.31で全体をフィットした結果も示してあります。少なくともこの程度データを再現した結果を示す必要があります。
今後の第2波に向けて対策を立てるのであれば、まず、これまでの予測モデルの結果とデータのベンチマークが必要です。これだけデータが出た現在、予測モデルの検証がほとんど行われない、もしくは示されていないことは甚だ問題です。これはこの連載の冒頭に述べたことです。早急に予測モデルの詳細な検証を示すべきです。
表1
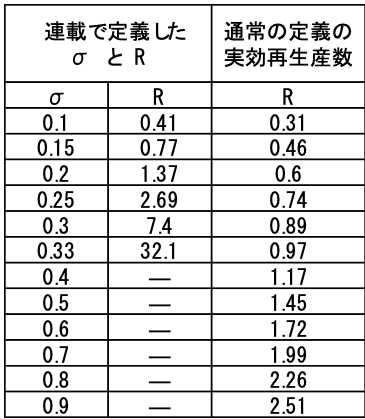
(*注)連載④,⑤,⑥でR=0.77、R=1.37は誤記で、R=1.37、R=7.4の表記の間違いでした。また、このRの定義は、通常の実効再生産数とは異なっているので、通常の実効再生産数との換算表を表1に示します。これまでは、ひとりの人から感染する全ての人数でしたが、通常の実効再生産数は次世代までの感染者数です。原子炉の実効倍増係数と同じだと指摘を受けました。モンテカルロ計算では、このような世代解析等が直接、かつ簡単にでるのがひとつの特長です。








