



総務省統計サイトより(編集部)
偏差値は受験を経験した人は嫌と言うほど付き合わされた言葉です。大学は偏差値でランク付けされ、受験者は自分の偏差値との差に悩みます。しかし「偏差値とは何か」と聞かれてきちんと答えられる人はそれほど多くはないかもしれません。理解はしていなくても自分の偏差値が55で志望校の合格ラインが偏差値65なら「無理」と諦めなければいけない。その時の恨み(?)が「偏差値教育」への批判につながっているのかもしれません。
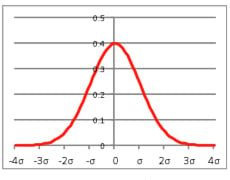
偏差値とは相対的にサンプル(例えば受験生全体)のどのあたりにいるかを表す数字です。サンプルの数字の平均値からどれくらいサンプル中のそれぞれの数字がばらついているかを示すために標準偏差(シグマ:σ)というものがありますが。偏差値の値は、平均点を50点、標準偏差を10とした場合の相対的位置を示しています。例えば、ある人の偏差値が60点なら上位15%の中にいることを示します。偏差値70なら上位2.3%、80なら0.13%で千人に1人の秀才ということになります。
ただ、ここで示したパーセンテージになるためには、点数の分布が正規分布になっている必要があります。試験の点が正規分布になっていれば、受験生の数をグラフにすると平均点近くが多くなり、平均点から離れるほど少なくなる、ベルの形に似たベルカーブと呼ばれる曲線になります。実際には、試験の点の分布がきれいな正規分布になることはあまりないでしょう。試験によっては、満点付近に高学力の人が集まり、下の方にも大きな塊があったりするのが普通です。百人の受験者の中で同じ30番、あるいは平均点より5点高い、と言っただけでは試験科目ごとの点数のバラツキで意味合いが違ってしまいます。しかし、平均点と標準偏差はどんな点数の分布でも計算できるので、同じ平均点50点と10点の標準偏差を持つ正規分布になると考えると、ある人が相対的にどの程度の位置にいるかを知ることができるわけです。
試験の点数は正規分布にならない場合も多いのですが、身長や体重といった身体的特徴の多くは正規分布になります。これは母集団(学校単位、職業単位、国単位などなど)に関係なく成立します。それどころかハツカネズミの体重、チンパンジーの腕の長さなど、ほとんどどんな場合でも動物の身体的特徴の統計を取ると正規分布になります。知能指数、IQは、そもそも知能の定義も明確ではないため疑問のある数値なのですが、IQの分布は正規分布になるために、知能も身長などと同様な身体的特徴と見做されています。
しかし、身長や体重はなぜ正規分布になるのでしょう。血液型は日本人ではA型、O型、B型、AB型がそれぞれ、40%、30%、20%、10%で分布しています。この比率は民族ごとに違っていて、インディオはほぼ全員がO型です。血液型に限らず、えんどう豆の花の色の比率など特定の遺伝子で決まる形質はある形質を表す遺伝子が遺伝子プールの中でどの程度の割合になっているかで決まり、正規分布などにはなりません。
身長や体重が正規分布になるのは身長、体重の決定に影響のある遺伝子が多数あるからだと考えられます。つまり、個々の遺伝子は一定の割合で発現するのですが、それがいくつも合わさると結果的には正規分布を作り出すのです。沢山の要素(そしてそれぞれが一定の分布を持っている)が合わさって全体として正規分布になるのは、中心極限定理という数学理論に裏付けられています。頭の良さを示すIQも、知能というものがいくつもの遺伝的の要素が組み合わさった結果なので、正規分布になると考えられます。実は、「いくつもの要素」は遺伝子だけとは限りません。生活環境、本人の努力など要素の数が増えても、むしろ増えれば増えるほど正規分布により近づいていくはずだということを中心極限定理は示しています。
正規分布は受験の偏差値のように広く使われていますが、前に書いたように何でも正規分布になるわけではありません。サイコロを振って出る目は、1から6まで同じですし、コインを投げて表が出る確率と裏が出る確率は半々です。ところで、コインの投げを一回でなく100回繰り返すと表が出る個数は平均で50個になります。この100回のコイン投げ何度も繰り返して表が出る個数を数えると、表が出る個数の頻度は50個の所を頂点に、それより表が出る個数が多くなるほど、あるいは小さくなるほど頻度が少なくなる正規分布のベルカーブに近い形になります。
さらにコインの投げの数をどんどん増やしていくと、表が出るコインの個数のグラフはなめらかな正規分布に近づいていきます。これは正規分布が多くの要素が合わさったものでも、コイン投げという非常に簡単なモデルでも同じ結果を示していることを示しています。これはちょっと不思議なことではないでしょうか(私には驚くべきことのように思えます)。
沢山の要素が合成されるという意味では、株式相場の価格変動も同じです。株価の将来(正確には金融派生商品の価値の理論値)を予測するブラックショールズ式は、金融商品の価格変動は正規分布に従っているという前提を置いています。多くの要素が関連するものを正規分布と仮定して考える別の例としては、GEが採用して有名になった6シグマという品質管理技法があります。
例えば、ピザの到着時間の平均が30分だったとしましょう。「平均30分でお届けします」。これはちょっと困ります。平均30分と言われても、10分で届くかもしれないし、50分かかるかもしれない。平均は無意味ではありませんが、平均だけでなくバラつきが少ないことが大切です。では「概ね30分±5分でお届けします」ではどうでしょう。概ね?まだ安心できません。「30分±5分でお届けします。このお約束が守れないのは100万回に3.4回以下です」これなら良さそうです。35分以内にはまず間違いなくピザが到着するでしょう。
シックスシグマは数字で表される品質の指標が一定の範囲、標準偏差σの6倍以内に収まるようにプロセスの改善をすることを目標にしています。これは品質の良し悪しには多くの要素が関係するので、品質指標の数字は正規分布になるはずだという前提を置いているからです。正規分布であれば、標準偏差σの6倍の外側に数字がはみ出るのは100万回に3.4回にしかなりません(実際には標準偏差σの6倍、6シグマの外側になるのは10億回に2回なのですが、6シグマ技法では平均値自身が1.5シグマ分ずれることを勘定に入れて、4.5シグマとして計算します)。
6シグマによる改善では、例えばピザの到着時間に影響がある要素を一つ一つバラツキがないように改善します。改善が進むほど標準偏差σの値、数字のバラツキ度合は小さくなり、ついには標準偏差σの6倍の範囲が目標としている数字の許容範囲の内側になります。GEは非常に広範囲の製品、金融業、サービス業を展開し、そのほとんどで6シグマによる改善で大きな成果を上げました。業種が違っていても、プロセスのバラツキは正規分布になるという前提は有効だったわけです。
ただ、正規分布の威力を過大評価する危険もあります。金融業の黄金方程式であるブラックショールズ式でノーベル賞を受賞したショールズとマートンが参加したヘッジファンドのロング・ターム・キャピトル・マネージメント、LTCMは1998年にアジア通貨危機に端を発したロシアの財政危機でロシア国債の市場が閉鎖されたために破綻しました。正規分布でばらつくはずの価格変動が平均から大きく離れたところでは理論通りにならず標準偏差の10倍、計算上は1兆の10億分の1しか起きないはずの事象が、あっさり起きてしまったのが直接の原因でした。
正規分布は便利ですが、平均からはるか何シグマも離れたようなところの発生確率が現実世界でも正しいかどうかは十分な吟味が必要です。あるいは受験での偏差値の計算のように元々の点数の分布が試験問題の難易度や受験生により平均を中心としたベルカーブにならない場合の適用も慎重でなくてはいけません(と言って無理をして受験に失敗することも多いようですが)。理論という道具は万能薬ではありません。道具を使いこなすにはそれなりの腕前が必要になることは確かです。








