



厚生労働省の毎月勤労統計調査の不正事件で、政府は予算案を修正する異例の閣議決定を行った。厚労省の発表によると、従業員500人以上の企業について2004年以降、他の府県では全数調査を求める一方、東京都だけはその1/3の企業の名簿で抽出調査をしていた。
これ自体は大した問題ではない。抽出率の逆数3をかけて集計すれば、精度は落ちるが、サンプルに偏りがなければ平均賃金は大きく変わらない。ところが厚労省は東京都の抽出調査を全数調査と偽り、他の県の全数調査の数字と単純に合計したため、賃金の高い東京の比重が下がり、全国の平均賃金が過少に集計された。
厚労省の「再集計」によると誤差は平均0.6%程度だというが、影響はそれにとどまらない。昨年1月にも「賃金の伸び率が急に上がった」という疑問が出ていた。朝日新聞によると、賃金上昇率は昨年6月に前年同月比3.3%と、入れ替えがなかった事業所に比べて2%ポイントも高い伸びを示した。これは東京都の抽出調査の結果に抽出率逆数をかけてデータを復元したものだった。
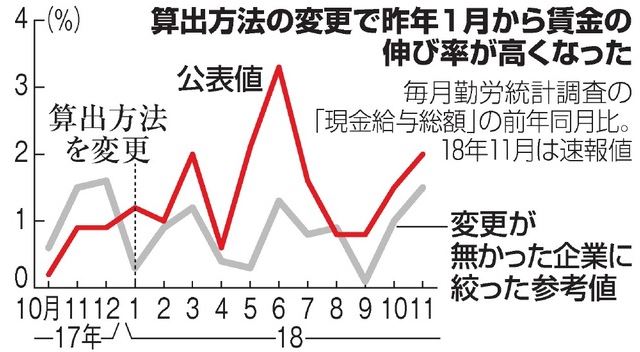
朝日新聞デジタルより
厚労省の追加資料には産業分類ごとの逆数が出ているが、1倍から12倍までアドホックに設定している。今から遡及して集計するには、抽出調査の数字にこの逆数をかければいいのだが、2010年以前はその逆数表がないという。
だから0.6%というのは今ある資料から推定した数字で、2004年から2011年までの正確な賃金データは存在しないというのが正しい。産業別の抽出率もバラバラなので、部門によってはもっと大きな差が出る可能性もある。事業所ごとの個票データが残っていれば集計しなおして逆数を推定できるが、この個票データが「保存期間を満了し廃棄済」だという。
なぜこんな常識はずれのルール違反をしたのだろうか。厚労省は説明していないが、東京都から「抽出調査にしてほしい」という要望があったともいわれる(小池都知事は否定している)。最大の疑問は、抽出調査でやるにしても、その集計のとき(去年1月からやったように)抽出率逆数をかけなかったのはなぜかということだ。これは手間もかからないし、全数調査との誤差も小さいので、厚労省以外にはばれないだろう。
統計のプロが、こんな初歩的なミスをするとは思えない。これは私の推測だが、統計処理はコンピュータでやっているので、2004年にこっそり抽出調査に変更したとき、処理システムのバグで逆数がかかっていなかったのではないか。東京都だけの例外処理ができなくても、出てくる平均賃金はそう大きく変化しないので、設定したシステム業者以外にはわからない。
サンプルは3年に1度変更するので、そのとき東京都だけ抽出調査になっていることは厚労省の担当者も気づいたはずだが、「今さら全数調査に変更すると、失業給付を遡及して追加するとか大変なことになる。逆数をかけているはずだから抽出のままでいいだろう」と見過ごしてきた――ということではないか。
それなら去年1月にシステムを変更して逆数をかけたとき、過去の数字も訂正して説明すべきだったが、これもこっそりやったので、少なくともそのとき以降は過失ではなく、意図的なデータ偽装と隠蔽である。「システム業者の設定ミス」ということで幕引きさせてはいけない。
ただし野党がいうように「アベノミクスで賃金が上がったように見せる偽装」ということはありえない。システム変更で平均賃金が上がったのは衆議院選挙の直後であり、数字を操作するなら2017年10月の総選挙の前にやるだろう。国会ではくだらない政局がらみの話にしないで、政府統計をどう合理化するか建設的な議論をしてほしい。








