>>>①はこちら
>>>②はこちら
>>>③はこちら
>>>④はこちら
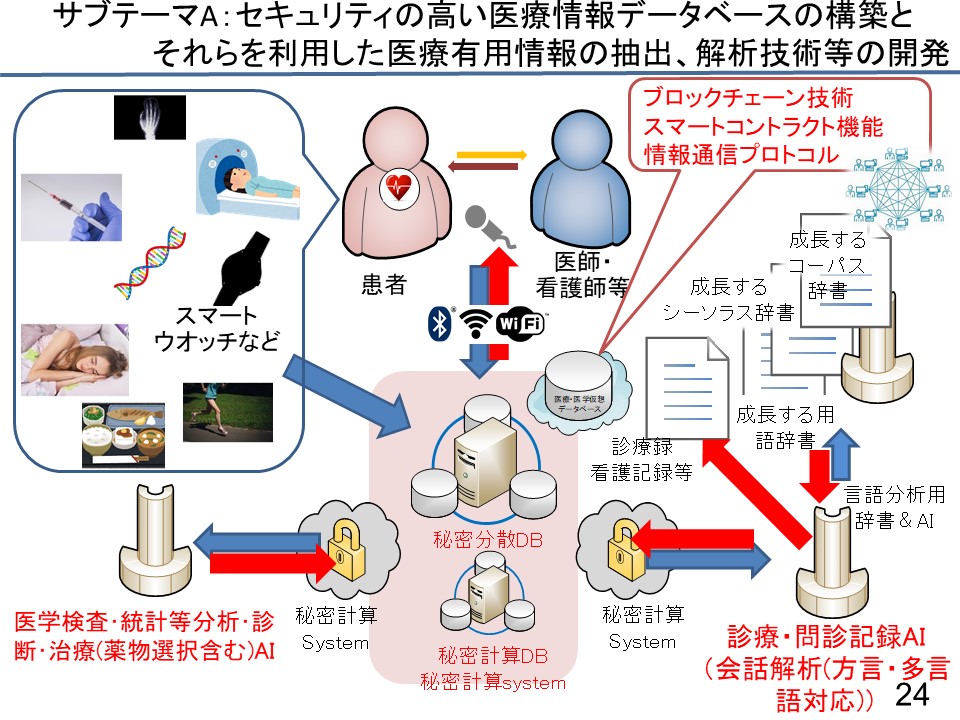
このプロジェクトで一番大きな課題はセキュリティです。このセキュリティを解決するために、1人の患者さんの情報をクラウドに分散して置く秘密分散方式でのデータベースの構築は、今では、技術的には可能です。分散した情報をもとに秘密計算していく、解析していくことも可能です。
1カ月ほど前に、ソフトバンクと日本ユニシスが開発したシステムが発表されていましたが、セキュリティーの観点で非常に大きなことです。個人がデータベースにアクセスできる権利を三重のチェックを設けて制限していくシステムです。
例えば、皆さんが病院・クリニック外いるときに、どうしてもこれを調べたいというときでも、スマートフォンとパソコンと、顔面認証(あるいは、虹彩認証・静脈認証)といった3段階のレベル認証システムです。しかも、秘密分散方式ですから、情報が一部だけ漏れても何の情報か分からない形にすることが可能です。
ハッカーとはいたちごっこになるかもしれませんけれども、現時点では、世界的に見て非常にセキュリティの高いデータの保存システムが、日本の中でも出来上がっています。

そして、話言葉をテキスト化する際の一つの大きな課題は医療用の辞書です。いろいろな言葉をテキスト化するソフトが開発されつつありますが、専門用語というのは非常に難しいですし、薬でも一般名なのか、商品名なのか、商品名でもジェネリックだと商品名が違うのでこれも大きな課題です。それを一つの形でまとめていくのは、簡単なようで意外に難しいので、37万語からなる医療用辞書を作りました。
編集部より:この記事は、医学者、中村祐輔氏のブログ「中村祐輔のこれでいいのか日本の医療」2019年10月5日の記事を転載させていただきました。オリジナル原稿をお読みになりたい方は、こちらをご覧ください。